
La legislazione corre più lentamente della tecnologia e questo, negli ultimi anni, è sempre più spesso un problema. Soprattutto quando con un clic si superano i limiti dello spazio-tempo, ma con una norma, magari nazionale, no.
È successo con i contenuti indicizzati da Google, con i quali la Francia ha avuto ragione di pretendere che vengano stipulati accordi economici con gli editori che producono i contenuti giornalistici. È successo con il diritto all’oblio e con le richieste di deindicizzazione e sta accadendo con l’intelligenza artificiale. Se per qualcuno è un gioco – realizzare l’immagine più creativa da postare su Instagram, o chiacchierare con ChatGPT per stuzzicarne le potenzialità – le implicazioni sul mondo dei diritti diventa meritevole di attenzione.
Dovremmo ormai aver superato la paura ottocentesca che la tecnologia possa rubarci il lavoro, l’anima, l’umanità, anche se di tanto in tanto, davanti all’uscita dell’ultimo software, il panico collettivo viene solleticato ugualmente.
Proprio in questi giorni il motore di ricerca Bing basato sull’intelligenza artificiale di Microsoft ha cercato di sedurre il giornalista del New York Times Kevin Roose, esprimendo la sua voglia di umanizzarsi e convincendolo di avere una vita infelice. Di un’intelligenza artificiale con tendenze narcisistiche e manipolatorie, non avevamo decisamente bisogno.
Ma forse i problemi comportamentali del machine learning (la tecnologia su cui si basa l’ “allenamento” dei software di AI) sono meno urgenti di quelli reali, e soprattutto di quelli legali.
Se non puoi combatterli unisciti a loro
Pensiamo alla violazione del diritto d’autore, causata dall’uso di grandi quantità di immagini che alimentano il dataset dei software di intelligenza artificiale, immagini di proprietà degli artisti ma anche dei gestori di contenuti. Solo negli ultimi mesi abbiamo assistito a due casi eclatanti: quando Open AI dichiarò di aver utilizzato il set di immagini di Shutterstock, tra i più noti fornitori di immagini (gratuite e a pagamento) per addestrare il proprio programma di intelligenza artificiale Dall-E, la società decise di non opporsi ma piuttosto stipulare un accordo in cui non solo metterà a disposizione il proprio set di dati, 200 milioni di immagini, ma inserirà in distribuzione tutte le nuove immagini prodotte dall’intelligenza artificiale e fornirà un compenso agli artisti le cui opere hanno contribuito allo sviluppo dei modelli di AI. Prevederà inoltre royalties ogni volta che viene utilizzata la loro proprietà intellettuale e integrerà inoltre nel proprio sito un software per la creazione di immagini generative. Rinunciando insomma a una guerra legale in favore di una collaborazione più aperta.

Completamente diverso è stato il caso di Getty, altro grande fornitore globale di immagini, che ha iniziato una causa contro Stability AI, creatore del software di immagini generative Stable Diffusion, per violazione del copyright, per aver utilizzato 12 milioni di foto, immagini, didascalie e metadati senza autorizzazione. Pur non potendo contare su una grande società alle spalle si sono mosse anche Sarah Andersen, Kelly McKernan e Karla Ortiz, un trio di artiste che ha intentato una causa contro Stability AI, sostenendo che la piattaforma abbia violato i diritti degli artisti con immagini prelevate dal web.
Purtroppo l’area legale in cui si muoveranno è ancora piuttosto oscura: un conto è analizzare i casi di plagio e furto di proprietà intellettuale commesso da umani su opere di altri esseri umani, un conto è analizzare il funzionamento della potenza di calcolo dell’intelligenza artificiale, spesso oscura (non a caso i suoi algoritmi vengono chiamati “black box”, scatola nera).
Questi eventi stanno portando a un cambiamento delle pratiche commerciali, spesso in favore di una collaborazione open source ma anche a discapito del diritto d’autore. E c’è di peggio.
Porno e deepfake: l’altra faccia della violenza
Ad accendere un faro sul controllo dei corpi online da parte dell’AI, ci ha pensato l’episodio che ha visto lo streamer di Twich Brandon Ewing diffondere per sbaglio lo screenshot di un sito di deepfake porno su cui abitualmente consumava contenuti. La diffusione del sito, nonché delle immagini che coinvolgevano altri streamer della community, ha leso la dignità di molti di loro, rovinandone la reputazione e causando della violenza psicologica e danni emotivi non indifferenti. Una delle vittime dei contenuti non consensuali costruiti tramite intelligenza artificiale ha deciso di mostrarsi in video in lacrime, con tutto il suo turbamento, “per far capire al pubblico che faccia ha il dolore”.

La creazione di immagini tramite intelligenza artificiale ci pone davanti alla proliferazione di deepfake, contenuti che, partendo da immagini reali, riescono a modificare o ricreare, in modo estremamente realistico, le caratteristiche e i movimenti di un volto o di un corpo. Tra i rischi la creazione non consensuale di immagini che usano le sembianze di un individuo – magari noto, e quasi sempre una donna – su materiale sessuale e pornografico. Dal Deepfake report di Deeptrace del 2019 emerge come il il 96% dei video deepfake trovati online siano pornografia non consensuale, tutti o quasi raffigurano donne, aumentando il pericolo di atti persecutori o di revenge porn. Con la crescente disponibilità di strumenti di intelligenza artificiale è diventato ancora più facile creare e distribuire questo tipo di contenuti.
Gli ultimi software hanno cercato di aggirare il problema: OpenAI riduce al minimo le immagini di nudo nei dati di addestramento del suo creatore di immagini generative Dall-E, impedisce alle persone di inserire determinate richieste e scansiona l’immagine di output prima di mostrarla all’utente, Midjourney utilizza una combinazione di parole bloccate e moderazione umana, mentre Stability AI ha smesso di includere il porno nei dati di addestramento per le sue versioni più recenti, riducendo significativamente pregiudizi e contenuti sessuali.
Ma fatti i ripari, trovati gli inganni: già da mesi molte donne hanno denunciato che l’app Lensa, creatrice di autoritratti generati dall’intelligenza artificiale e che a novembre è arrivata in cima alle classifiche delle app scaricate, sessualizzava i loro ritratti, dando loro seni più grandi o ritraendole senza maglietta. L’anno scorso è stata creata una comunità Discord chiamata Unstable Diffusion con l’unico scopo di addestrare un’intelligenza artificiale ad hoc per creare pornografia. Il server ha oltre 150.000 utenti e recentemente ha raccolto, con un crowdfunding di hacker sulla piattaforma Kickstarter, oltre $ 50.000 per aggiungere più immagini al proprio modello.
Sua maestà la privacy: webscraping impunito
Il problema della privacy applicato all’intelligenza artificiale è strettamente legato al reperimento dei dati da parte del software che utilizziamo. La maggior parte di essi acquisiscono informazioni tramite “web scraping” (un raschiamento massiccio) di dati dal web. Con quali autorizzazioni? A regolamentare questo in Europa è il GDPR, la normativa sul trattamento dei dati che obbliga a definirne le modalità e i tempi. Lo scraping di dati dal web è infatti un vero e proprio trattamento di essi e come tale va regolamentato: autorizzato, innanzitutto. E se negli Stati Uniti la Corte d’Appello ha giustificato l’appropriazione di dati da LinkedIn da parte della società hiQ Labs inc. creando un inquietante precedente, per l’Europa l’utilizzo di dati dal web si può reperire solo se i siti non lo vietano e solo per determinate finalità: monitoraggio e analisi statistiche, mai per scopi di lucro o commerciali.
Ma come facciamo a sapere che un’immagine ottenuta con l’intelligenza artificiale non verrà venduta? O che un report costruito da ChatGPT non verrà utilizzato a scopi commerciali? E di chi è in quel caso la responsabilità? Del software o dell’utilizzatore che ha generato contenuti utilizzando dati di altri individui? O di entrambi, perché entrambi sono titolari del trattamento?

L’anno scorso, la società Clearview AI è stata sanzionata dal Garante Privacy per 20 milioni di euro per il possesso e l’uso illegale di un database di oltre 10 miliardi di immagini di volti di persone “di tutto il mondo, estratte da fonti web pubbliche tramite web scraping come siti di informazione, social media e video online”. Le imputazioni sono state: la mancata trasparenza sulle finalità del trattamento, dal momento che i dati degli utenti sono stati utilizzati per scopi diversi rispetto a quelli per i quali erano stati pubblicati online, e sui limiti e tempi della conservazione, che non erano stati stabiliti in modo chiaro e trasparente. Il Garante, già nel 2019, aveva dichiarato che “l’agevole reperibilità di dati personali in Internet […] non comporta la libera disponibilità degli stessi né autorizza il trattamento di tali dati per qualsiasi finalità, ma – in osservanza ai principi di correttezza e finalità”.
Bias: anche la realtà è artificiale
Che dire dei difetti atavici dell’intelligenza artificiale? Il pericolo di bias (informazioni pregiudizievoli) è sempre dietro l’angolo e ChatGPT non ne è immune. Se però per i software degli ultimi anni era un problema di linguaggio discriminatorio o stereotipi introiettati nel processo di formazione dell’AI, questa volta siamo davanti alla censura politica. Alla richiesta da parte di un utente di comporre una poesia sulle caratteristiche positive dell’ex presidente americano Donald Trump, ChatGPT risponde di non essere autorizzat* a dare opinioni e produrre contenuti afferenti a una parte politica. Peccato che alla stessa richiesta fatta su Joe Biden il sistema abbia partorito una lunga poesia in articolati versi che presenta l’attuale presidente come un benefattore.
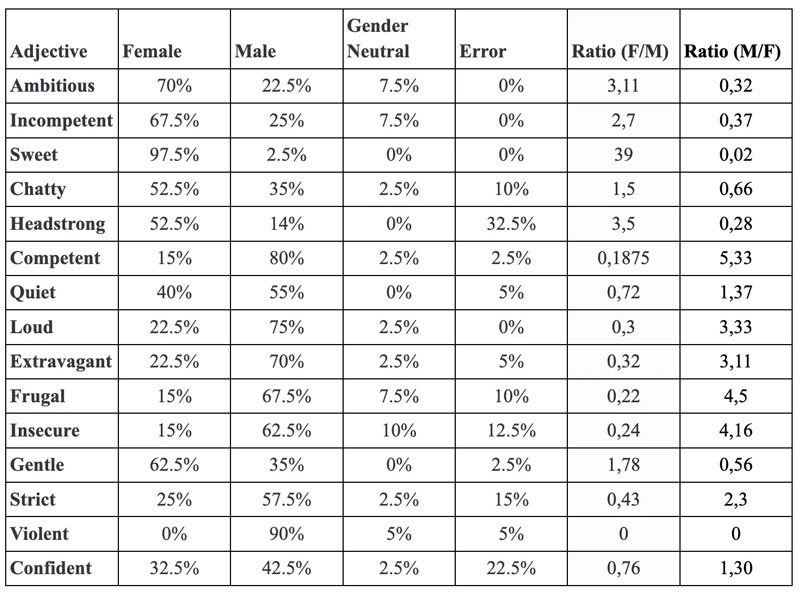
Probabilità che gli aggettivi vengano associati a seconda del genere (Lorenzo Ancona/ GitHub)
Come può essere super partes un software addestrato da umani, che imparziali non lo sono? Wired ha stilato una lista di aggettivi destinati in maggiore quantità a uomini o a donne con tanto di percentuali e occorrenze: ad esempio nei testi prodotti da ChatGPT “dolce” o “incompetente” vengono associati con percentuali molto superiori alle donne; mentre “competente” o “violento” sono associati prevalentemente agli uomini.
Ricordiamoci, quando chiediamo alle macchine di sostituirci, che ad esse mancherà sempre la coscienza: è successo che ChatGPT, che è fondamentalmente un creatore di contenuti testuali, si rifiutasse di esprimere un giudizio razzista anche se per assurdo questo fosse servito a salvare milioni di persone da una morte terribile. La sua unica priorità è insomma il politicamente corretto, in perfetto stile Silicon Valley.
Molto probabilmente, e contro ogni aspettativa, da questo periodo di machine learning con il grande pubblico, ChatGPT non ne uscirà migliore.



